
Data migrations in Ruby on Rails
In the world of programming and IT, people are eager to give all their activities scientific character and provide scientific proof for everything. When I got into the Ruby world, I felt something completely different. Yukihiro Matsumoto created a language to facilitate communication between people through code, and this has led to a special community of philanthropic people. It seems to me that it is precisely the conciliar spirit that is felt in this community: all people share similar values, as well as have similar intuitions and relate to each other with love in the gospel sense of the word, which means that they do not need any proof since, according to Berdyaev, the proof is needed for different hostile intuitions.
The discovery of the concept of the conciliar spirit inspired me to write an article (after I had realised that proof arguments were hardly possible). My goal is to collect arguments that will resonate in the hearts of developers and give rise to the intuition that mixing schema migrations and data migrations is ineffective because it can lead to operational and maintenance problems.
Mixing data migrations and schema migrations
The official Rails documentation says that migrations are used for schema migrations, i.e. they are limited to DDL queries. But the lack of a ready-made solution for data migrations leads to the misuse of schema migrations for data transformation. It seems that this problem is specific to Rails and similar omakase frameworks for backend development. When there is no out-of-the-box solution for schema migrations, there is nothing to misuse.
Positive aspects of mixing data migrations and schema migrations
There is a positive aspect of doing data transformations in the same way as schema transformations. That is, create increments between versions that can run both forwards and reverse. In terms of continuous delivery, it should be possible to deploy any version of the system so that the data schema and status are correct and consistent. It is also convenient to see all the increments as a single list in the file system and treat them uniformly during system operation.
Issues of mixing data migrations and schema migrations
Data migrations are different from schema migrations and create a different runtime load profile. This creates problems that are much talked about in the English-language blogosphere. I have collected the most common (perhaps all) arguments and highlighted operational, maintenance, and questionable issues.
Operational problems
Data migrations take longer than schema migrations. This increases the downtime for deployments. For large volumes, the downtime may exceed the timeout time set for migrations, and manual intervention may be required.
Long data migration transactions increase the likelihood of deadlocks in the database.
To prevent the indicated operational problems, you can use static code analysis tools during the development phase. For example, Zero Downtime Migrations and Strong Migrations gems.
Violation of the Single Responsibility Principle
Schema migrations are a Ruby DSL (Domain Specific Language) for SQL DDL constructs and their binding. As long as we use DSL, reasonable quality is guaranteed by manually checking that the migration can run both forwards and reverse. If we are wrong about the migration, we will not be able to continue the development and will immediately fix it.
As soon as we go beyond the DSL for data manipulation, we violate the Single Responsibility Principle. The consequence of this violation is an increased risk of errors. If we want to eliminate it, then we are going to cover migrations with tests, but…
There are no tests (at least adequate, cheap)
The author of the Ruby On Rails Data Migration article rolls back previous migrations to test data migrations and verifies that the target migration performs the desired data changes. In a large application, this will take a monstrously long time and will increase the cognitive load on the team by making them read and write such tests. It is undesirable to have data migration logic inside the Rails migration code where it is so difficult to test. I will tell you where to place this logic in the section of solutions.
Maintenance issues when using model classes in migration
For data migration logic, it is very convenient to use the code from models and the tools of the ORM ActiveRecord language instead of SQL.
But this may lead to the following problems:
- The model class may be renamed or deleted. Then a non-existent constant error will be received.
- Validations may be added to the model to prevent changes from being made.
- The model may contain callbacks with side effects that the author of the migration code does not expect.
For these situations, there is a temporary solution that helps override the model class right in the migration. This is a duplication of knowledge and cannot be considered an exemplary solution.
Maintenance issues when using SQL for migrations
If we want to use SQL commands directly, thus trying to avoid using models in migrations, we will face the following disadvantages of this approach:
- The logic is more complex than the model code logic. It is more complex since it is less concise, at a lower level of abstraction, in a different language (SQL), which we relatively rarely use.
- If there are JOINs, this is a serious duplication of knowledge expressed in model relationships.
- With prolonged processing, it is impossible to track progress and understand whether the processing is still in progress or a deadlock has already occurred.
Exceptions when it is permissible to perform data migrations in schema migrations
Data migrations can be included in schema migrations if a rollback migration is impossible without it.
For example, turning a nullable field into a field with a default value, or vice versa.
Since migrations must be rolled back, we must ensure the reverse transformation. Thus, updating the value is indispensable.
The request will look trivial:
UPDATE table SET field = 'f' WHERE field IS NULLThe entire migration might look like this:
class ClientDemandsMakeApprovedNullable < ActiveRecord::Migration def up change_column_null :client_demands, :approved, true change_column_default :client_demands, :approved, nil end def down execute("UPDATE client_demands SET approved = 'f' WHERE approved IS NULL") change_column_null :client_demands, :approved, false change_column_default :client_demands, :approved, false endend
Generally speaking, if you have a large amount of data in the table, you should not do this and you need to resort to more sophisticated methods. For example, do not run a migration in production, but make all changes manually and then replace the migration file and the version in the database.
Possible solutions
Rejecting a solution due to the scanty volume of application or data
Until a certain point in growth, you can close your eyes to mixing problems. These old “sins” will not harm you in any way. You can quit at any time and even act according to the situation. Please tell me in the comments if I’m wrong.
Using a single mechanism for schema and data migrations, provided that high-quality rollback migrations are written, will ensure the possibility of continuous delivery.
But if the application, base, or team grows bigger, it is better to resort to more discipline in order to reduce losses.
Moving data migrations from the codebase to the ticket system
Since the biggest concern is the presence of data migrations within schema migrations, getting them out of there is a top priority. You can agree not to treat data migrations as part of codebase. They can be debugged in REPL on a staging server and saved in a ticket for manual use in production.
This will be an improvement, but there are serious drawbacks to this approach:
- Data migration code cannot be found when searching by model name;
- There is no thought process of development when using a test;
- There is no continuous delivery.
The pragmatic philosophy urges you not to trust anyone and yourself in particular. You cannot trust a script that has been debugged using staging data. This data may be incomplete. Test-driven code development gives the highest quality results I know.
I admit that there may be projects where this approach is justified, but I cannot recommend it for the projects in which I participate.
Moving data migrations to Rake tasks
A more reliable, affordable and efficient method is to create Rake tasks for data migrations. It is convenient to cover them with tests. While writing a data migration test, I often have insights about requirements and manage to solve potential business problems.
Recently, the project had a data migration Rake task that was not covered with a test. During the code review, no one noticed that the entire array was overwritten instead of just being added an element. The typo led to data corruption and the need to restore data from a backup in a selective manual mode. In the process of writing the test, such a logical typo could not have been made. Therefore, tests are our great helpers in the thought process.
It is important to keep track of the idempotency of such transformations. A Rake task is likely to be completed more than once in production.
Although this solution is simple and quite attractive, it still has a significant drawback. It does not automatically deploy any version of the product with a single command. It can be used in a situation when product development does not occur in frequent increments, rarely rolls back, and you can keep track of manual steps during deployments. But this method is not suitable for continuous delivery.
Moving data migrations to separate inner classes within migration
Mark Qualie suggests adding a nested class definition and an up method, which determines the data migration logic, to the schema migration code. Thus, the “locality” of knowledge about schema changes and related data changes is achieved. Here’s some sample code from the article:
class AddLastSmiledAtColumnToUsers < ActiveRecord::Migration[5.1] def change add_column :users, :last_smiled_at, :datetime add_index :users, :last_smiled_at end class Data def up User.all.find_in_batches(batch_size: 250).each do |group| ActiveRecord::Base.transaction do group.each do |user| user.last_smiled_at = user.smiles.last.created_at user.save if user.changed? end end end end endend
The author proposes to implement this logic in the following way:
Dir.glob("#{Rails.root}/db/migrate/*.rb").each { |file| require file }AddLastSmiledAtColumnToUsers::Data.new.up
What’s more, the author proposes to put this code into an asynchronous Job and add logging and tracking of completed migrations, such as storing the version of schema migrations in the database.
Using full gems for data migrations in the style of schema migrations
When the team is large, the application is large, or data migrations occur in every second or third release, it can pay off using a ready-made, fully functional gem for data migrations in the style of schema migrations.
This solution already meets the requirements of continuous delivery because tracking a data migration version is performed in the same way as for schema migrations.
There are a lot of similar gems, but there are no super popular ones among them. Apparently, this is because the scale of the problem does not reach the desired size.
The data-migrate gem has the largest number of stars (> 670) and links from articles. By the way, it has the most well-groomed Readme. It only works with Rails 5+.
Two more gems with similar experience, but support for Rails 4+:
- rails-data-migrations (> 95 stars)
- nonschema_migrations (> 55 stars)
The name of the latter is especially remarkable. It screams the opposition of schema migrations and NON-schema migrations.
I did not audit the codes of all these gems because the approach of Rake tasks is enough for my kind of project. But finding them was one of my incentives to write this article. To me, they are a sign of the severity of the problem that can be faced as the application grows.
All of them allow you to generate a data migration class in the db/data project folder, which is next to the traditional db/migrate containing schema migrations:
rails g data_migration add_this_to_thatAnd then run and check the status with commands like these:
rake data:migraterake db:migrate:with_datarake db:rollback:with_datarake db:migrate:status:with_data
A good idea to simplify testing is to extract the migration logic to a nested class inside the migration, as in the previous example.
Comparative characteristics of solutions
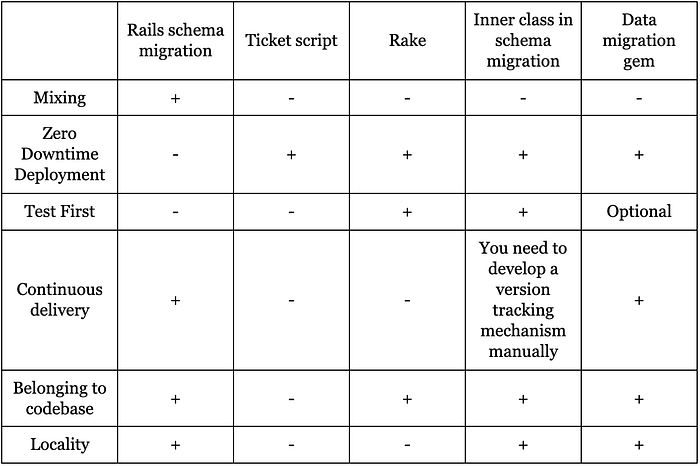
Horizontally — solutions about the placement of data migration logic.
Vertically — qualities, namely:
- Mixing — the fact of using a single schema migration mechanism for data migration;
- Zero Downtime Deployment — the ability to minimize the runtime of migrations by using only the most needed and fastest operations to change the schema during deployment;
- Test First — the convenience of developing data migration logic by writing a test of adequate complexity;
- Continuous delivery — the ability to roll back a product of any version in one step;
- Belonging to codebase — placing the data migration code inside the codebase, as opposed to one-time scripts in the ticket system;
- Locality — the presence of data migrations in a standardized codebase location, which can be found by navigating through the project rather than by keyword searches.
Conclusion
When data migrations occur every few months, then manual Rake tasks are a pragmatic solution.
But when this happens more often, it is worth looking at full-scale automated solutions that use a ready-made gem and are performed in the style of schema migrations. This will ensure meeting continuous delivery requirements.
Thus, the data migration problem should be addressed as the project grows — in the architectural style appropriate to that scale. It seems that this approach has every chance of making the development process adequate.
